O słowniku
1. PIERWOWZÓR
Przedstawienie słownika
Pierwszy tom Słownika Etymologicznego Nazw Geograficznych Śląska (skrót SENGŚ) wydano w formie papierowej w 1970 roku. Drugi tom ukazał się po dłuższej przerwie w 1985 roku. Kolejne części wydawano już w miarę regularnie, co rok lub dwa, trzy lata.
Autorem pierwszego tomu był Stanisław Rospond, zaś jego wydawcą — Państwowe Wydawnictwo Naukowe, Wrocław, Warszawa. Kolejne tomy powstawały jako prace zbiorowe. Drugi i trzeci — pod red. Stanisława Rosponda i Henryka Borka, czwarty — pod red. Henryka Borka, piąty i następne — pod red. Stanisławy Sochackiej. Od piątego tomu wydawcą i miejscem wydania stał się: Instytut Śląski, Opole, od roku 1994 występujący pod nazwą Państwowy Instytut Naukowy Instytut Śląski w Opolu. Całości przypisano numer ISBN 83-7126-041-5. Poszczególne tomy otrzymały też własne numery ISBN jak w zestawieniu poniżej (z powtórzeniem w przypadku tomów od czwartego do siódmego).
| Tom | Zakres | Data | Autor/redaktor | ISBN |
|---|---|---|---|---|
| I | (A–B) | 1970 | Stanisław Rospond | 83-7126-041-5 (całość) |
| II | (C–E) | 1985 | pod red. Stanisława Rosponda i Henryka Borka | 83-01-05425-5 |
| III | (F–G) | 1986 | pod red. Stanisława Rosponda i Henryka Borka | 83-01-07006-4 |
| IV | (H–Ki) | 1988 | pod red. Henryka Borka | 83-01-07934-7 |
| V | (Kl–Kos) | 1991 | pod red. Stanisławy Sochackiej | 83-01-07934-7 |
| VI | (Kos–Lig) | 1992 | pod red. Stanisławy Sochackiej | 83-01-07934-7 |
| VII | (Lig–Miez) | 1994 | pod red. Stanisławy Sochackiej | 83-01-07934-7 |
| VIII | (Mię–Niż) | 1997 | pod red. Stanisławy Sochackiej | 83-7126-085-7 (tom VIII) |
| IX | (Noc–Path) | 1999 | pod red. Stanisławy Sochackiej | 83-7126-119-5 (tom IX) |
| X | (Pato–Poz) | 2002 | pod red. Stanisławy Sochackiej | 83-7126-157-8 (tom X) |
| XI | (Poż–Roz) | 2004 | pod red. Stanisławy Sochackiej | 83-7126-190-X (tom XI) |
| XII | (Roż–Sow) | 2005 | pod red. Stanisławy Sochackiej | 83-7126-195-0 (tom XII) |
| XIII | (Spad–Szyw) | 2007 | pod red. Stanisławy Sochackiej | 978-83-7126-226-5 (tom XIII) 978-83-7511-051-7 (tom XIII) |
| XIV | (Ściana–Weł) | 2009 | pod red. Stanisławy Sochackiej | 978-83-7126-248-7 (tom XIV) 978-83-6210-514-4 (tom XIV) |
| XV | (Wem–Wrzes) | 2011 | pod red. Stanisławy Sochackiej | 978-83-7126-277-7 (tom XVI) 978-83-6210-596-0 (tom XVI) |
| XVI | (Wrzesień–Żyznów) | 2014 | pod red. Stanisławy Sochackiej | 978-83-7126-300-2 (tom XVI) 978-83-7511-196-5 (tom XVI) |
| XVII | (A–Ż) | 2016 | pod red. Stanisławy Sochackiej | 978-83-7126-325-5 (tom XVII) |
Opis zawartości tomów
W pierwszym tomie zdefiniowano reguły redakcyjne: „Hasła nazewnicze winny obejmować: 1) podstawową, zrekonstruowaną i aktualną formę, jej wariant niemiecki według stanu z 1939 r. oraz ewentualny, gwarowy polski; 2) charakter obiektu i jego lokalizację; 3) szeroką dokumentację historyczną z wyszczególnieniem przekazów źródłowych, ściśle transliterowanych, z adresem bibliograficznym podanych; 4) na końcu ma być uwzględniona etymologia. Przy identycznych powtarzających się hasłach podano kolejną numerację. Ponieważ wartość naukowa słownika geograficznego nie może być wyłącznie językoznawcza, ale też historyczno-osadnicza i geograficzna, dlatego ta właśnie dokumentacja źródłowa została podana w szerokim zakresie.”
Zadeklarowano też zalecenia co do sposobu redakcji części etymologicznej:
„Zwięzła etymologia wg typu strukturalnego jako nadrzędne kryterium (I, II, III, IV) i wg
znaczeniowo-leksykalnego drugorzędnego kryterium (1, 2, 3). Ponadto podany jest wyraz i nazwa
osobowa, od których pochodzi hasło nazewnicze. W miarę potrzeby uwzględniono też materiał
porównawczy. Czasem przy większych miejscowościach są odsyłacze do literatury etymologizującej te
nazwy.
Nie są etymologizowane chrzty polskie i stereotypowe nazwy terenowe niemieckie, które najczęściej
były »chrztami« niemieckimi pierwotnie polskich nazw.”
Sposób redakcji treści, jak również zakres prowadzonych prac zmieniał się w kolejnych tomach, o czym informowano czytelnika w ich wstępach.
W drugim tomie ograniczono zakres opracowania do obszaru Śląska mieszczącego się w granicach Polski. Posłużono się też nazwami według podziału administracyjnego aktualnego na dzień 21 XII 1978.
W czwartym tomie uznano za celowe zrezygnowanie ze schematu klasyfikacyjnego zapisywanego skrótowo na rzecz metody bardziej opisowej, pozwalającej wyjaśnić w języku naturalnym i w miarę szczegółowo formalny sposób powstania nazwy i jej pierwotne znaczenie toponimiczne.
W czwartym tomie dość liczną grupę stanowią hasła zaczynające się od słowa „Huta”. Zwykle są to hasła dwuwyrazowe, np. „Huta Agaty”, jednak pojawiają się również nazwy z opcjonalnie potraktowanym słowem „Huta”, np. „(Huta) Bobrek”. Ponadto od czwartego tomu praktycznie zaczęto wykorzystywać „Wykaz urzędowych nazw miejscowości w Polsce”, t. 1-3, Warszawa 1980-1983 (Wyk I, Wyk II, Wyk III) jako źródło współczesnych danych referencyjnych. Wcześniej głównym materiałem źródłowym dla tego typu danych był „Spis miejscowości Polskiej Rzeczypospolitej Ludowej”, Warszawa 1967 (PRL).
W piątym tomie ważną rolę odegrały nazwy kopalń. Podczas redagowania haseł w tym przypadku postąpiono nieco inaczej niż w przypadku hut. Zamiast wpisywać słowo „Kopalnia” jako pierwszy człon redagowanych nazw zdecydowano, by utworzyć podsłownik w słowniku. Wprowadzono więc hasło „Kopalnia”, a pod nim umieszczono nazwy kopalń uporządkowane alfabetycznie, już bez tego pierwszego członu. W efekcie powstały hasła spoza przedziału alfabetu (Kl-Kos) zadeklarowanego dla tego tomu.
W piątym tomie postanowiono również zamieszczać objaśnienia wszystkich nazwy współczesnych, rekonstruowanych, potocznych i będących chrztami administracyjnymi. Wywód etymologiczny zaś polegać miał na wskazaniu podstawy słowotwórczej nazwy, w oparciu o dokumentację źródłową wraz z materiałem porównawczym. W ten sposób chciano rozszerzyć treść słownika, bo w poprzednich tomach nie podawano etymologii dla nazw będących chrztami administracyjnymi URM oraz nie objaśniano nazw niemieckich nieposiadających zapisów polskich.
W szóstym tomie kontynuowano redagowanie części etymologicznych haseł, ale w bardziej rozwiniętej formie opisowej. Od tego tomu praktycznie (deklaratywnie zaś dopiero od dziewiątego tomu) zaczęto podawać materiał historyczny ze „Słownika geografii turystycznej Sudetów” - źródła gromadzącego oronimy. Materiał ten ma jednak charakter wtórny, bez precyzyjnego cytowania oryginalnych źródeł.
Podczas redakcji siódmego tomu, jak wynika z treści zamieszczonych w jego wstępie, wśród narzędzi stosowanych przez autorów pojawił się system komputerowy.
Wraz z postępem prac nad słownikiem rozszerzała się też lista analizowanych źródeł historycznych. Przykładowo w ósmym tomie wykorzystano po raz pierwszy kilkutomową pracę „Schlesisches Urkundenbuch”.
W tomie dziewiątym zaczęto wykorzystywać kartotekę Flurnamen znajdującą się w Instytucie Herdera w Marburgu (FlM, pierwotna postać skrótu Fl M).
W praktyce od tomu dziesiątego podawane są polskie nazwy przejściowe (skrót NP), używane w 1945 r. i później na Śląsku. Wymieniane one były już wcześniej, ale bez nowych oznaczeń. Materiał ten został wyekscerpowany przez autorki z „Monitora Polskiego” i dokumentów Komisji URM. Został też opublikowany w artykule M. Choroś, Ł. Jarczak „Wykaz przejściowych nazw miejscowych na Opolszczyźnie w latach 1945-1948” w t. 43 pisma Onomastica w roku 1998.
Jako współczesny materiał referencyjny od tomu dziesiątego rozpoczęto używać „Spis miejscowości w Polsce”, wyd. ok. 2000 r. (SpisM I, SpisM II). Także od tego tomu podawane zostały lokalizacje zgodnie z wprowadzonym od 1999 r. nowym podziałem administracyjnym kraju, z gminami, powiatami i województwami.
W przygotowaniu dwóch pierwszych tomów drugiej dziesiątki, tj. tomów jedenastego i dwunastego, wykorzystano założenia metodologiczne wypracowane we wcześniejszych opracowaniach.
Trzynasty tom wzbogacono o informacje pochodzące z dodatkowy źródeł, m.in. dotyczące współczesnego nazewnictwa stawów milickich (skrót SM).
Od tomu czternastego, zgodnie z sugestiami recenzentów, zaczęto podawać etymologie nazw będących chrztami administracyjnymi URM oraz chrztami niemieckimi z okresu międzywojennego. Poszerzono także bazę źródłową o kolejne prace J. Domańskiego — badacza wrocławskiego, który zajmował się m.in. nazwami śląskich rzek. W 2008 roku PIN – Instytut Śląski w Opolu zakupił od spadkobierców J. Domańskiego rękopiśmienną kartotekę zabranych materiałów dotyczących hydrografii. Materiały te zostały zarejestrowane w słowniku z odpowiednim adresem źródłowym. Ponadto współczesne nazwy wodne zostały uzupełnione o nazewnictwo zawarte w publikacji „Nazewnictwo geograficzne Polski, t. 1: Hydronimy, cz. 1: Wody płynące, źródła, wodospady; cz. 2. Wody stojące”, Warszawa 2006.
W kolejnym, piętnastym tomie, na warsztat autorów trafiły dodatkowe źródła: „Regesty śląskie” (RegŚl), „Urkunden zur Gesichte des Bistums Breslau im Mittelalter” (SUr), „Lustracja dróg województwa krakowskiego z roku 1570” (LDKrak), „Monumenta Poloniae histrorica” (MPH) i inne. Niektóre pozycje wykorzystano jednakże w małym zakresie. Od tego tomu w materiale historycznym i opisie etymologicznym zaczęto umieszczać odwołania do stron internetowych. Było ich stosunkowo niewiele, łącznie kilkanaście przypadków. W obecnej wersji słownika większość z nich zastąpiono odwołaniami do źródeł bardziej pierwotnych.
W tomie szesnastym w roli źródła referencyjnego pojawiało się „Rozporządzenie Ministra Administracji i Cyfryzacji z dnia 13 grudnia 2012 r. w sprawie wykazu urzędowych nazw miejscowości i ich części”, Dziennik Ustaw, 2013 r., poz. 200 (DzU13 poz. 200).
Ostatni, siedemnasty tom, wydano w 2016 roku. Był to tom uzupełniająco-korygujący, zawierający hasła zaczynające się od A do Ż.
2. OBECNA WERSJA
Prace nad cyfrową wersją SENGŚ zaowocowały powstaniem dwóch aplikacji webowych — systemu prezentacji (oferującemu publiczny dostęp do zawartości słownika w trybie odczytu/przeglądania) oraz systemu edycji (oferującej chroniony dostęp do zawartości słownika w trybie odczytu/zapisu).
Obecna, elektroniczna wersja SENGŚ, kojarzona jest głównie z systemem prezentacji. Na jego przyjaznym interfejsie wystawiono funkcje przeglądania oraz przeszukiwania zawartości słownika. Słownik ten może być wykorzystywany na różnorakie sposoby: jako materiał referencyjny podczas prowadzenia prac naukowych, jako źródło informacji dla osób zainteresowanych historią, jako pomoc w budowaniu tożsamości lokalnych społeczności, jako materiał dla językoznawców. Z powodzeniem do tej listy dołożyć można zastosowania geograficzne, kulturoznawcze, krajoznawcze, ale też historyczno-osadnicze, bibliograficzne i inne.
Mimo dużego zaangażowania prace nad obecną wersją słownika jeszcze się nie skończyły. Oprócz nanoszenia korekt, mającymi na celu poprawę jakości danych, cały czas odbywa się rozszerzanie zakresu gromadzonych treści, jak również udostępnianych w słowniku funkcji.
Więcej szczegółów dotyczących modelu danych SENGŚ można znaleźć w artykule: T. Kubik, Digital Transformation of the Etymological Dictionary of Geographical Names. Applied Sciences. 2021; 11(1):289. https://doi.org/10.3390/app11010289.
Struktura słownika
W elektronicznej wersja słownika zgromadzono hasła w podziale na tomy odpowiednio do pierwowzoru. Dodatkowo do słownika dołączono tom 18, przeznaczony na nowe hasła, opracowane od zera, niepojawiające się w oryginale. Jako podstawę nazewniczą nowododawanych haseł przyjęto najbardziej aktualną i używaną formę i wersję językową lub w przypadku nazw zaginionych, czyli nie stosowanych obecnie (oznaczanych symbolem †) ostatnio używaną formę w oryginalnej wersji językowej. Za niecelowe uważa się tworzenie sztucznych rekonstrukcji nazewniczych.
Aby zachować logikę przeglądania haseł pierwowzoru, w dostarczonej elektronicznej wersji zastosowano podział toponimów na: abstrakcyjne (odpowiadające hasłom nagłówkowym oraz hasłom reprezentującym porównania) oraz konkretne (odpowiadające hasłom posiadającym opis). Przyjęto terminologię, w której „toponim abstrakcyjny typu rozwinięcie” reprezentuje hasło nagłówkowe (oznaczane na listach ikoną w kształcie rombu z zaokrąglonymi kątami), „toponim abstrakcyjny typu porównanie” odpowiada porównaniu (reprezentowanemu na listach ikoną w kształcie koła), „toponim konkretny” zaś to rekord zawierający opis konkretnego toponimu (oznaczany na listach ikoną w kształcie odpowiadającym klasie toponimu).
Spośród wymienionych jedynie toponimy konkretne posiadają osobne podstrony, na których wyświetlane są szczegółowe opisy. Każda z takich stron posiada sekcje prezentujące dane ogólne (nazwa, klasa toponimu, charakterystyka obiektu, atrybuty obiektu, lokalizacja), dane historyczne (z listą form nazewniczych ze wskazaniem źródeł) oraz dane etymologiczne (z opisem pochodzenia danej nazwy, jeśli takowy został opracowany).
Wprowadzone rozszerzenia
Zakres przekazywanych informacji w elektronicznej wersji słownika poszerzono względem oryginału o dodatkowe elementy. Dodano atrybut pozwalający sprecyzować lokalizację geograficzną. Dodano też miejsce na linki do zasobów dostępnych on-line. Wprowadzono taksonomię klas toponimów oraz uporządkowano terminy stosowane do określenia charakterystyki obiektów.
Lokalizacja toponimów w obecnym słowniku może być reprezentowana na trzy sposoby: poprzez podanie przynależności administracyjnej, poprzez podanie lokalizacji w sposób opisowy oraz poprzez określenie współrzędnych geograficznych w układzie WGS84 (zapisanych wewnętrznie w formacie WKT). Choć zaplanowano możliwość prezentacji lokalizacji toponimów na mapie, to jednak z uwagi na braki danych (w oryginalnym słowniku nie pojawiały się współrzędne geograficzne, a podczas cyfryzacji słownika nie udało się ich pozyskać) taka mapa jeszcze się nie pojawia. Pewnego nakładu pracy wymaga również korekta lokalizacji opisowej (teksty pojawiające się przy tym atrybucie są w większości przypadków wynikiem automatycznego przetwarzania i mogą zawierać błędy). Jeśli zaś chodzi o przynależność administracyjną, to w elektronicznej wersji słownika starano się podążać za oryginałem. Ponieważ oryginał wydawano na przestrzeni wielu lat, przynależności te mogą nie odpowiadać stanowi dzisiejszemu. Dlatego przynależnościom przypisano rok, w jakim należy je rozpatrywać (rok ten wynikał z założeń podjętych przez autorów oraz roku wydania danego tomu słownika).
Zaprojektowane modele danych
Projektowanie elektronicznej wersji słownika odbywało się z uwzględnieniem sposobu organizacji treści dostarczonych w pierwowzorze, jak również wymagań systemów informatycznych oraz planowanych rozszerzeń. W wyniku prac stworzono dwa modele danych: model relacyjny oraz model grafowy.
Model relacyjny posłużył do zaimplementowania schematu bazy danych, będącego podstawową działania zbudowanego później portalu. Schemat ten powstał ostatecznie w wyniku zastosowania mapowania obiektowo-relacyjnego.
Celem opracowania modelu grafowego było otworzenie możliwości na zintegrowanie powstającego słownika z innymi systemami realizującymi ideę danych powiązanych. W efekcie model ten powstał na bazie modelu RDF, z uwzględnieniem konstrukcji stosowanych we wnioskowaniu RDFS++. Według tego modelu odbywać się ma generowanie i publikowanie trójek reprezentujących elementy zgromadzonych danych. Na chwilę redagowania tego opisu słownik nie oferował jeszcze punktu dostępowego obsługującego protokół SPARQL (ang. SPARQL endpoint), z którego trójki te można byłoby pobrać albo poprzez który można byłoby je przeglądać.
Sposób dostępu
Dostęp do danych zawartych w bazie danych odbywa się poprzez interfejs systemu prezentacji (portalu SENGS dostępnego publicznie, działającego pod adresem https://sengs.e-science.pl), jak również poprzez interfejs systemu edycji (aplikacji webowej z ograniczonym dostępem, pozwalającej przeglądać i modyfikować zawartość relacyjnej bazy danych).
Najwięcej szczegółowych informacji zwykli użytkownicy słownika mogą znaleźć na odpowiednich podstronach toponimów konkretnych. Przekazywane tam treści można podzielić na trzy części: ogólną (zawierającą m.in. nazwę toponimu i jego atrybuty), historyczną (zawierającą listę referencji do materiałów źródłowych) i etymologiczną (z opisem etymologii danej nazwy). Ponadto słowik oferuje funkcje pozwalające na wyszukiwanie i przeglądanie jego zawartości (poprzez przeglądanie list toponimów i tomów, wyszukiwanie pełnotekstowe, z filtrowaniem wyników, jak również poprzez przeglądanie indeksów).
3. CYFRYZACJA SŁOWNIKA
Podczas przygotowywania elektronicznej wersji słownika napotkano na liczne trudności wynikające ze sposobu organizacji treści w oryginalnym słowniku. Najwięcej problemów sprawiło przetwarzanie danych pochodzących z pierwszych czterech tomów, przy czym pierwszy tom okazał się szczególnie trudny do analiz.
Cyfryzacja słownika przebiegała etapami, z licznymi nawrotami. Na początku przetworzono skany oryginalnego słownika celem otrzymania surowego tekstu. Następnie tekst skonwertowano do postaci strukturalnej, dążąc do uzyskania zgodności z zaprojektowanym modelem danych. Na tym etapie przygotowano również zestawienia metadanych bibliograficznych cytowanych materiałów źródłowych celem wygenerowania identyfikatorów wykorzystywanych do tworzenia linków. Odpowiedzialność za wygenerowanie tych identyfikatorów przeniesiono na system AZON. Tak przygotowanym wsadem zasilono bazę danych SENGŚ.
Podczas przygotowywania danych wsadowych intensywnie wykorzystywano wyrażenie regularne. Pozwalały one na masowe usuwanie częstych i systematycznych błędów oraz na przygotowanie danych w postaci strukturalnej. Kolejne prace nad poprawą jakości danych odbywały się już po ich załadowaniu do bazy danych oraz uruchomieniu prototypu słownika. Wykorzystywano przy tym interfejs systemu edycji, jak również robocze zrzuty bazy danych.
W trakcie prac zauważono, że istnieją niepoprawne porównania, zdefiniowane jako związki między nazwą wskazaną a nazwą bądź nazwami docelowymi (oddzielonymi od nazwy wskazanej skrótem cf.). Analizując je dokładniej zauważono przekierowania cykliczne (nieprowadzące do żadnego toponimu z opisem, te starano się wyeliminować) oraz przekierowania puste (gdzie docelowa nazwa okazywała się nazwą niewystępującą w słowniku, te pozostawiono bez zmian mając nadzieję, że brakująca nazwa kiedyś pojawi się w słowniku).
Ponadto zauważono przypadki ewidentnych błędów polegających na „ukryciu” opisu toponimów konkretnych w opisach innych toponimów (te korygowano niemalże natychmiast).
Prace nad poprawą jakości danych prowadzone są w trybie ciągłym. Użytkownicy elektronicznej wersji słownika mogą zobaczyć te zmiany po ich utrwaleniu w bazie danych.
Część ogólna
W części ogólnej można zobaczyć nazwę toponimu (z wariantami) oraz jego atrybuty (włącznie z wprowadzonymi rozszerzeniami, w tym: lokalizacją geograficzną, klasyfikacją i charakterystyką obiektów, jak również linkami zewnętrznymi).
Obecnie w linkach zewnętrznych pojawiają się odwołania do: Atlasu Historycznego Miast Polskich (http://atlasmiast.umk.pl/), Elektronicznego słownik hydronimów Polski (ESHP, https://eshp.ijp.pan.pl), The Historic Gazetteer (http://gov.genealogy.net), Meyers Gazetteer (https://www.meyersgaz.org), Geoportalu (https://pzgik.geoportal.gov.pl/imap), Polska-org.pl (https://polska-org.pl), Wikipedii, map Google i innych serwisów. Niestety, ponieważ są to odwołania do serwisów zewnętrznych, nie ma gwarancji co do ich persystentności w dłuższym horyzoncie czasu. Problem ten zaznaczył się podczas przygotowywania danych bibliograficznych źródeł historycznych deponowanych w systemie AZON (gdy przygotowane wcześniej linki do źródeł przechowywanych w cyfrowych archiwach należało zmienić z uwagi na przebudowę tych archiwów).
Sprawę klasyfikacji toponimów rozwiązano definiując kategorie: choronimy, chrematonimy, dendronimy, hodonimy, hydronimy, etnonimy, mikrotoponimy, ojkonimy, oronimy, urbanonimy, a następnie przypisując kolejne toponimy do którejś z tych kategorii. Przypisanie to pozwala usprawnić wyszukiwanie oraz zapewnia tzw. lepsze doświadczenie użytkownika. Niestety, podobnie jak charakterystyka obiektów (patrz dalej), klasyfikacja toponimów może zmieniać się w czasie. Dokonana więc ich kategoryzacja obowiązuje na dzień wydania słownika.
Nieco inaczej postąpiono podczas deklarowania charakterystyki obiektów. W oryginalnym słowniku dość swobodnie posługiwano się terminami mającymi oddać charakter obiektu odpowiadającego opisywanej nazwie. Pojawiały się więc rzeczowniki w liczbie pojedynczej i mnogiej (np. las, lasy), ze zdrobnieniami (np. lasek, potoczek) jak również wyrażenia złożone (np. miejsce do połowu ryb i gajówka, teren położony po obu stronach drogi). Co więcej, aby skrócić zapis stosowano skróty (np. m. — miejscowość), przy czym bez konsekwentnego ich użycia (pojawiały się różne skróty tego samego terminu, nawet w obrębie jednego tomu). W cyfrowej wersji słownika ujednolicono i uporządkowano te terminy. Ostatecznie listę tych terminów zamknięto na poziomie nieco ponad 320 elementów. Należy jednak podkreślić, że opis charakterystyki obiektu z samej natury opisywanych toponimów nie może być permanentny. Nazwy miejsc bowiem często ewoluowały niezależnie od obiektów, których dotyczyły, same zaś obiekty zmieniały charakter - rosły, malały, rozdzielały się i łączyły. Z uwagi na temporalność zagadnienia tak naprawdę należałoby zbudować dość zaawansowany model danych, uwzględniający nie tylko przebieg zmian nazw na przestrzeni wieków, ale również wszelkiego rodzaju nieciągłości (bo nazwy znikały i pojawiały się, niekoniecznie w tym samym tempie co obiekty, do jakich je przypisywano), niespójności (nazwy gromadzone mogły być w różnych systemach nazewniczych - tj. w różnych językach, w różnych systemach administracyjnych) oraz braki (czasami wiadomo, że istniał jakiś obiekt, ale brakuje jego nazwy itp.).
Kolejnym problemem okazała się identyfikacja języka, w jakim wyrażane były nazwy toponimów, warianty nazw, jak również nazwy wymieniane w części historycznej (z odniesieniem do źródeł). W pierwszych tomach oryginalnego słownika jako hasła pojawiały się zarówno nazwy polskie, jak i nazwy wyrażone w innych językach (głównie nazwy niemieckie). W kolejnych tomach to się zmieniło.
Regułą redakcyjną było umieszczanie przy danym haśle wariantów nazw umieszczonych w nawiasach, w językach dopełniających opis, czasem wyrażanych w gwarze. To znaczy jeśli główną nazwę (hasło w ortografii literackiej) podano w języku polskim, to w nawiasach pojawiała się nazwa w języku niemieckim. Bądź odwrotnie, jeśli główna nazwa była podana w języku niemieckim, to w nawiasach podawano nazwę w języku polskim. Przy czym czytelnik musiał domyślać się, która nazwa jest po polsku, a która po niemiecku lub innym języku. Przy nazwach zwykle nie było żadnej wskazówki świadczącej o użytym języku. Jedyne, co mogło w tym przypadku pomóc, to kontekst (opis hasła, etymologia, użyty alfabet, źródła, obecność dopełniacza). Czasem można było natknąć się na skróty (pol., niem., mor. ...), ale nie wszędzie.
Co więcej, nie zawsze stosowano tę regułę redakcyjną. W szczególności pomijano ją wtedy, gdy opisywane toponimy nie posiadały wariantów nazw (z uwagi na fakt, że ich po prostu nie było). Ponadto zdarzało się, że lista wariantów nazw dla danego toponimu liczyła kilka pozycji, nie mówiąc już o występowaniu nazw gwarowych.
W elektronicznej wersji słownika postanowiono uzupełnić opis toponimu o informacje o języku, w jakim podawane są konkretne nazwy. Każdej więc nazwie i każdemu wariantowi nazwy przypisano wewnętrznie znacznik identyfikujący język zgodnie z BCP 47. Na interfejsie użytkownika objawiło się to dodatkowym literałem, umieszczanym za wariantem nazwy ("polski", "niemiecki" itp.).
Przyjęto, że:
- jeśli jakaś nazwa funkcjonowała w danym systemie administracyjnym, a co za tym idzie danym
systemie nazewniczym (języku używanym w danym państwie), to znacznik języka powinien być przypisany
według tego systemu. Stąd nazwie Charlotte przypisano znacznik języka o wartości „niemiecki”,
choć źródłosłów tej konkretnej nazwy jest francuski;
- jeśli w jakiejś nazwie wystąpiły litery z danego alfabetu bądź zbitki liter charakterystycznych
dla danego języka, one definiowały znacznik języka przypisany tej nazwie.
Jest to pewne uproszczenie i niedoskonałość, z którą użytkownicy SENGŚ powinni się liczyć.
Część historyczna
Zgodnie z deklaracją z pierwszego tomu materiał historyczny w słowniku powinien pojawiać się w kolejności chronologicznej, z podaniem ściśle transliteracyjnej formy nazewniczej, ze skrótem reprezentującym źródło informacji (z tomem, rokiem, pozycją w źródle — zwykle stroną, czasem też z numerem katalogowym dokumentu). W przypadku braku materiału historycznego pojawiać się ma odsyłacz do R s.v. = S. Rospond: „Słownik nazw geograficznych Polski Zachodniej i Północnej”, t. I i II, Wrocław Warszawa 1955 (s.v. = sub voce).
W rzeczywistości materiał historyczny w słowniku był redagowany różnie, z licznymi wyjątkami od zadeklarowanych reguł. Opisy zamieszczane przy poszczególnych hasłach przyjmowały formę powtarzających się zestawień o schemacie dającym się wyrazić w notacji EBNF w sporym przybliżeniu w następujący sposób (t. 1):
zestawienie ::= <nazwy> <skrót> <data_pozycja> ";"
nazwy ::= <nazwa> { "," <nazwa> }
skrót ::= [etykieta] [tom] ","
<data_pozycja> ::= [rok] [pozycja] {"," [rok] [pozycja]}
Przybliżenie, o którym mowa, wiąże się z tym, iż w tomie pierwszym pojawiały się wyjątki wypadające poza schemat. Przykładowo, dla toponimu „Bielawa (2)” (tom 1, str. 145) materiał historyczny podano w postaci:
Bela inferior, Bela superior, Bela, in Bielau, zu Bela CS XIV, 1300~, 86; XXII, 1329, 68; 1333, 176; XXIX, 1335, 33; Neder Bele, Bielau, Langen K45 1370, 33; Lange Bil, in Langbil J I, 1666, 728, 732; Langenbielau WAPWr1, 1743, 86; Bielau, Langen- Ober Bielau, Mittel Bielau, Nieder Bielau, Neu Bielau Z V, 1785, 162; Bielawa, Langenbielau D96 142; Bielau, sł. Bielawy, Bela A87 1887, 40; Bielawa, Langenbielau Myc 16.
W takich przypadkach trudno było automatycznie stwierdzić, który wariant nazwy pojawił się w jakim źródle, a dalej, jaką przypisać mu datę i pozycję. Próba zestawienia atrybutów „po kolei” kończyła się otrzymaniem listy z brakującymi wartościami. Poniżej pokazano część zestawienia wygenerowanego „zdroworozsądkowo”, do miejsca wystąpienia kolejnych nazw:
Bela inferior, CS XIV, 1300~, 86 Bela superior, CS XXII, 1329, 68; Bela, CS XXII 1333, 176; In Bielu, CS XXIX, 1335, 33 Zu Bela, ?????
Uzyskana w ten sposób lista zwykle okazywała się niepoprawna. Między innymi dlatego, iż autor
stosował zabiegi skracające zapis. Na przykład usuwał z listy form nazewniczych powtarzające się
nazwy, bądź też cytował kilka form nazewniczych znalezionych w jednym źródle. W efekcie aby
znaleźć poprawne przypisania należało przeglądnąć wszystkie wymienione źródła i odpowiednio
przeredagować zestawienie.
Okazało się również, że autor odwoływał się czasem do źródeł będących słownikami nazw geograficznych
wraz z przypisanymi do nich datami. Wtedy zwykle umieszczał w zestawieniu na ostatnim miejscu formę
nazewniczą pełniącą rolę hasła w danym słowniku (pod którym pojawiały się inne przytoczone formy
nazewnicze). W takich przypadkach postanowiono, by do takiej formy nazewniczej przypisać datę
wydania danego słownika.
To nie kończyło jeszcze listy problemów. W materiałach historycznych pojawiały się wtrącenia oraz komentarze. Aby nad tym zapanować w elektronicznej wersji SENGŚ dla materiałów historycznych zaprojektowano model danych jak niżej (pomijając dla przejrzystości niektóre detale):
zestawienie ::= ([nazwa] [język]) [rok] <skrót źródła> [pozycja] [uwagi]
gdzie nazwa odpowiadała tekstowi zawierającemu formę nazewniczą, w postaci jaka pojawiła się w cytowanym źródle. Widoczna opcjonalność atrybutów w tym schemacie wynikała z braków odpowiednich danych w oryginalnym słowniku (by nie trzeba było generować wartości dla danego atrybutu jeśli w oryginalnym słowniku takich wartości nie zamieszczono).
Aby otrzymać poprawne zestawienia materiałów historycznych należało powtórzyć sporą część pracy wykonanej przez autora. Na szczęście sporo cytowanych źródeł doczekało się upublicznienia w wersji elektronicznej na stronach bibliotek i repozytoriów cyfrowych. Dzięki temu, iż autor wskazał pozycje w tych źródłach, podczas weryfikacji danych wystarczało sięgnąć do odpowiedniego miejsca, bez konieczności wykonywania pełnego przeglądu tego źródła. Jednak nie zawsze. Niektóre źródła były bowiem dokumentami o stronach oryginalnie nienumerowanych (jak manuskrypty, starodruki, rękopisy). Wtedy trudno było odnieść „pozycję w źródle” podaną przez autorów SENGŚ do jakiejkolwiek strony upublicznionego skanu tego źródła.
W efekcie podjętych prac udało się opracować poprawne zestawienia materiałów historycznych towarzyszących opisom toponimów. Dla przytoczonego wyżej przykładu „Bielawa (2)” fragment poprawnego zestawienia (z odnośnikami do źródeł historycznych) przedstawia się następująco:
Bela inferior, Bela superior 1300~ CS XIV 86 Bela 1329 CS XII 68 in Bielau 1333 CS XII 176 zu Bela 1335 CS XXIX 33
Przy okazji prac nad źródłami pojawił się kolejny problem. Autor odwoływał się często do oryginalnych dokumentów, podczas gdy upublicznione dokumenty, z których korzystano, bywały kopiami oryginałów, czy też innymi ich wydaniami. W szczególności trudno było zweryfikować nazwy podane po łacinie, bo w kopiach oryginałów nazwy te pojawiały się w innych formach (przetłumaczone na język niemiecki, z błędami literowymi itp.). Dobrą ilustracją tego zagadnienia jest przykład:
Andrzejowice (tom 1, s. 10) 2. ~ m., obok Opawy: Andreowicz villa Reg 1224, 280 (kopia z XVI w.).
Z zapisów w części historycznej można dowiedzieć się, że „Andrzejowice” było kiedyś nazywane
„Andreowicz villa”, a fakt ten datowany jest na 1224 rok. Jak można mniemać, autor przytoczył tu
treść wpisu Regestu 280. Niestety, podczas prac nad SENGŚ nie udało się dotrzeć do kopii Regestu z
XVI wieku (nie znaleziono jej elektronicznej wersji dostępnej on-line). Aby zweryfikować poprawność
tej informacji sięgnięto do dzieła: „Codex Diplomaticus Silesiae T.7, cz. 1 Regesten zur
schlesischen Geschichte. Erster Theil. Bis zum Jahre 1250” udostępnionego pod adresem:
https://www.wbc.poznan.pl/dlibra/publication/11938/edition/19423/content
(patrz 146 numerowana
strona lub 150 z kolei strona dokumentu pdf).
W dokumencie tym wyszukano fragment:
„Ferner verleiht er der Stadt sein Gut Andreowic nebst Zubehör und die villa des Lutco”.
To samo pojawiło się na stronie: http://www.dokumentyslaska.pl/Regesten/Reg%20num/0001-0729.html (należy wybrać 280). Tak więc "Adreowic" rzeczywiście istnieje w opublikowanych zasobach. Jednak zamiast „Andreowicz villa” występuje tam jako „Gut Andreowic" (niem.). Sięgnięto więc do kolejnego zasobu dostępnego on-line, gromadzącego cyfrowe wersje dawnych dokumentów dotyczących Śląska: http://www.dokumentyslaska.pl/ . Znaleziono tam, pod adresem http://www.dokumentyslaska.pl/kds%2003/1224%2009%2001%20hulin%20kds.html cyfrową wersję dokumentu z oryginalnym łacińskim tekstem, potwierdzającym poprawność nazwy „Andreowicz villa”.
„Preterea damus antedicte civitati nostram propriam villam nomine Andreowicz cum omnibus suis attinentiis et aliam villam Lutconis nomine Lubomirici cum suis omnibus attinentiis, quam commutavimus cum alia villa nomine Crawar.”
(część elektronicznej wersji opracowania „Kodeks Dyplomatyczny Śląska” Karola Maleczyńskiego, Wrocław 1964, Zakład Narodowy im. Ossolińskich - Wydawnictwo Polskiej Akademii Nauk (tom III, lata: 1221—1227))
Jest to tylko jeden z przykładów, który pokazuje skalę trudności podjętego zadania weryfikacji poprawności zapisów w części historycznej SENGŚ.
Jeszcze na etapie przetwarzania wstępnego dokonano transformacji zapisów dat przybliżonych do standardu EDTF (ang. Extended Date/Time Format). Przykładowo przekształcono zapisy ok. 1300 r. lub ca 1300 do zapisu zgodnego z tym standardem – por.:
Bogata lanca ok. 1300 CS XIV 170 → Bogata lanca 1300~ CS XIV 170 Wenglin ca 1305 Dom L 103 → Wenglin 1305~ DomL 103.
Podczas weryfikacji opisów i w trakcie korekty błędów starano się zachować informacje pochodzące z oryginalnego słownika. W wielu przypadkach obecne wpisy nie pokrywają się jeden do jednego z oryginałem (szczególnie te z pierwszego tomu). Za cel bowiem postawiono, by w miarę możności stosować referencje do źródeł, które upubliczniono w postaci elektronicznej. Dlatego w części historycznej może pojawić się inna numeracja stron lub nawet inny zapis jakiejś nazwy (bo w cytowanej wersji elektronicznej nazwa ta występuje w nieco innej formie niż forma wymieniona w oryginalnym słowniku).
W oryginalnej wersji Słownika materiał źródłowy był wykorzystywany w różnym zakresie oraz z różną intensywnością. Niektórymi źródłami posługiwano się mniej więcej tak samo. Dotyczy to np. URM czy R (referencje do nich pojawiają się podobnie często we wszystkich tomach). W innych wypadkach uwidoczniły się wyraźne różnice. Przykładowo pozycja PopTab (Pop-Tab) jest cytowana 21 razy w tomie czwartym, 12 razy w tomie piątym (od którego wykazywana jest w „Uzupełnieniach skrótów”), tylko 3 razy w tomie szóstym oraz 5 razy w tomie siódmym. Pojawia się ona tyko 2 razy w tomie dziesiątym, i to w odniesieniu do jednego toponimu „PODE KRZAMI”. Przyglądając się temu dokładniej można dostrzec, że poza kilkoma wyjątkami źródła te wykorzystano podczas opracowywania haseł z zakresu alfabetycznego od J do Ł.
Warto w tym miejscu zwrócić uwagę na system oznaczeń źródeł zastosowany przez autorów. Ponieważ pierwsze tomy powstawały jeszcze przed erą komputerów PC, zarządzanie danymi bibliograficznymi musiało odbywać się ręcznie. Dlatego, zgodnie z praktyką przyjętą w wydawnictwach naukowych, robiono zestawienia wykorzystywanych źródeł, przypisując im unikalne skróty (w obrębie danego tomu). Następnie używano tych skrótów w charakterze referencji podczas redagowania haseł. Można te skróty porównać do alfanumerycznych cytowań generowanych przez narzędzia do zarządzania bibliografią. Z tą jednak różnicą, iż w części skrótów ukryto hierarchiczną strukturę. Przykładowo, skróty przypisane do wydawnictw wielotomowych składały się z paru fragmentów, najczęściej: skrótu reprezentującego to wydawnictwo oraz identyfikatora reprezentującego tom. Ponadto przy skrótach pojawiały się dopiski mające na celu wskazanie konkretnej pozycji w danym źródle (zwykle strony w danym tomie). Poza tym w oryginalnym słowniku oprócz materiałów źródłowych jako osobne zestawienia zamieszczano wykazy literatury (zawierający zwykle listę artykułów związanych z dziedziną).
W świetle powyższego uporządkowanie materiałów źródłowych i ujednolicenie przypisanych im skrótów w poszczególnych tomach oryginalnego słownika okazało się nietrywialne. Przystępując do realizacji tego zadania przyjęto, że powstanie nowy, jednorodny system unikalnych skrótów. W systemie tym skróty miały otrzymać postać zbliżoną do tej zastosowanej w oryginalnym słowniku. Konkretna referencja do źródła (tj. referencja do fragmentu źródła, w którym wymieniona została dana forma nazewnicza) miała składać się ze skrótu reprezentującego źródło oraz literału reprezentującego pozycję w tym źródle. Poza unikalnością skrótów w systemie tym ważną rolę przypisano unikalnym identyfikatorom. Identyfikatory te zamierzano wykorzystać jako elementy adresów internetowych (linków), pod którymi spodziewano się opublikować szersze metadane źródeł i, w miarę możności, również cyfrowe wersje samych źródeł. Odpowiedzialność za generowaniem tych identyfikatorów przejąć miał system zewnętrzny (dokładniej — system AZON, pełniący rolę repozytorium cyfrowego).
Podczas prac nad cyfryzacją słownika szybko okazało się, że budowa nowego systemu skrótów ma liczne uwarunkowania. Część z nich pojawiła się już na etapie wektoryzacji skanów, część zaś podczas projektowania modelu danych dla budowanego systemu informatycznego.
Z uwagi na wymagania automatycznego przetwarzania tekstów koniecznym stało się poszerzenie pierwotnie jednoliterowych skrótów. Dzięki temu łatwiej byłoby je odróżnić od innych elementów. Dokonano więc następującego wstępnego mapowania:
A, B, D, H, J, K, N, O, P, R, Z, L → A87, A88, B52, D96, H10, J, K30, K45, N39, O, P39, R, Z, LDykc.
W mapowaniu pozostawiono pewne jednoliterowe wyjątki: J, O, Z. Powodem tej decyzji był fakt, iż skróty te przypisane były do dzieł wielotomowych, a ich stosowanie w słowniku polegało na specyfikowaniu odpowiednich zakresów, np. J I–J IV, O I, O II, Z I/1–Z I/5, Z II–Z XIII. Osobnym przypadkiem okazał się skrót R, który stosowany był dość konsekwentnie jako R s.v.
Ponadto należało dokonać przemianowania różnych formy oznaczania tego samego źródła w różnych tomach. I to również odbywało się nie bez trudności. Przykładowo pozycja E. Eichler, H. Walther, „Ortsnamenbuch der Oberlausitz” oznaczana była na kilka sposobów: Oberl (6 przypadków), Ortsnamenbuch (3 przypadki), DS28 (6 przypadków). W oryginalnym słowniku pojawił się też zapis pełny: (E. Eichler, Walther, Ortsnamenbuch der Oberlausitz, 1975, I, s. 117-118).
Idąc dalej, w tomie czwartym zastosowano oznaczenie Oberl, zaś w analogicznym wykazie skrótów dodano zapis Ortsnamenbuch (tylko do tomu drugiego). Skrótu DS28 w ogóle nie wykazano, chociaż był on wykorzystywany w tomie czwartym i siódmym.
Efekt ujednolicenia skrótów można zaobserwować na przykładzie zastosowania skrótów: Ortsnamenbuch I i Ortsnamenbuch II. Zaowocowało to wpisami typu:
[…] głuż. Kalau ← *Kalov- Ortsnamenbuch I 117 […] (pierwotnie: […] głuż. Kalau ← *Kalov- Oberl I, s. 117 – SENGŚ t. 4, s. 126)
Podobnych niejednoznaczności z jakimi przyszło się zmierzyć było więcej. Okazało się bowiem, że rozbieżności z oznaczaniu tego samego źródła w różnych tomach nie są systematyczne. Przykładowo, zidentyfikowano następujące dopasowania:
Dor (t. 4) = SJP (t. 4), Svob (t. 4) = Svoboda (t. 11), F (t. 2) = CB (t. 16), Meschgang (t. 13) = Ort O (t. 7), VHG (t. 14) = GQ (t. 7), : St (t. 1), ST (t. 2) = SUr (t. 15), Graebisch (t. 12) = Mund (t. 17).
Przy okazji uściślania oznaczeń przekształcono także skróty, które mogły prowadzić do niejednoznaczności przeprowadzanego mapowania. Przykładowo, dokonano zmian:
MUKA A. → MukaA, Bor A → BorA
Analogiczne przekształcenia nie ominęły pierwotnych skrótów:
Dom B, Reg D, Zych J, Zych K, Bor N, Paw N, RYMUT N, Słownik N, Karaś N, Hrabec N, Eichler N, Niec N, Dom O, Ort O, Bor P, Dom P, SOCH P, Recz P, Rymut P, Kopert R, Bor Z, Dom Z, Makarski Z, Malec Z, Bor L, Stoj L, Dom L
Pewne nieścisłości w oznaczeniach zidentyfikowano także w odniesieniu do map. Początkowo podawane były skróty ogólne, bez danych o arkuszach i latach wydań, np.: Helwig, Homann, Scultetus, W (w tomie pierwszym: Wieland Grod, Wieland Op, Wieland Rat), Wrede.
Korekta podobnych zapisów musiała odbyć się sukcesywnie. Na przykład zapis:
Blazeowiz, gemeinhin Blasewiz, Blaseyowiz Wieland.
zamieniono na:
Blazeowiz, gemeinhin Blasewiz, Blaseyowiz 1736 MpWielOppol.
Podobnie jak w przytoczonych przypadkach starano się usunąć rozbieżności oznaczeń dla następujących rozpoznanych dopasowań:
MH (t. 14) = MpWielWrat (t. 17), PGrot (t. 14) = MpWielJav (t. 17), Wieland M (t. 16) = MpWielMunst (t. 17), WSch (t. 14) = MpWielSchw (t. 17).
A w odniesieniu do innych map:
CGla (t. 14) = MpCGla (t. 17), MpRey (t. 17) = SKPreus (t. 17).
Po poprawkach i uzupełnieniach dla map Wielanda wprowadzono następujący system skrótów:
MpWielBreg, MpWielGlog, MpWielGrot, MpWielJav, MpWielKarn, MpWielLig, MpWielMunst, MpWielOels, MpWielOppav, MpWielOppol, MpWielRat, MpWielSag, MpWielSchw, MpWielTesch, MpWielWol, MpWielWrat
Podobnie zrobiono dla innych map.
Osobnym przypadkiem okazały się cytowania regestów śląskich. W oryginalnym słowniku cytowano je z użyciem skrótów w dwojaki sposób: jako Reg oraz CS VII/1, CS VII/2, CS VII/3, CS XVI, CS XVIII, CS XXII, CS XXIX, CS XXX/1, CS XXX/2. Spróbowano poradzić sobie z tym dualizmem wprowadzając następujący schemat mapowania numerów regestrów dla poszczególnych tomów:
CS VII/1 = Reg 1–729
+ Dodatki (niem. Nachträge)
CS VII/2 = Reg 746–1639
+ Dodatki — zakres: 1640–1647
CS VII/3 = Reg 1648–2615
CS XVI = Reg 2616-3542
+ Dodatki: 2617a–[brak ciągłości]–3337a
CS XVIII = Reg 3543–4599
+ Dodatki: 368a–[brak ciągłości]–4522a
CS XXII = Reg 4600–5278
CS XXIX = Reg 5279–6020
+ Dodatki: 5678–[brak ciągłości]–6002
CS XXX/1 = Reg 6021–6387
+ Dodatki: różne
CS XXX/2 = Reg 6388–6988
+ Dodatki: 6053a–[brak ciągłości]–6892
W efekcie doprowadziło to do wprowadzenia zmian jak w przykładach przedstawionych poniżej.
1) ADAMOWICE, t. 1
Adae villa Reg 1235, 471b; → Adae villa 1235 CS VII/1 211 = Reg 471b
2) †ANDREE VILLA, t. 1
Reg 1223, 274 (oryg.). → Andreas 1223 CS VII/1 144 = Reg 274 (oryg.)
w brakujących SU I 169 (nr 231) i KŚl III 77 (nr 289) jako villis Andree
3) CEREKWICA, t. 2
Czircwicza 1228 Reg 335 (oryg.); → Cyrcviza 1228 CS VII/1 171 = Reg 335 (oryg.);
Cerekuiz 1243 Reg 609 (oryg.); → Circkvicz 1243 CS VII/1 272 = Reg 609 (oryg.);
4) BĘDKOWO, t. 17
Benkovo 1236 Reg 496; → Benkovo 1236 CS VII/1 217 = Reg 496;
5) BIESTRZYKÓW, t. 17
Petrzoua 1234 Reg 444 (oryg.); → Petrzsowa 1234 CS VII/1 203 = Reg 440a (oryg.)
oraz dodano: Petrzsoua 1234 SU II 38 nr 60
W pierwszym przypadku należało dokonać mapowania do skrótu CS VII/1, zidentyfikować stronę zapisu oraz uwzględnić różnicę w strukturze tomu pierwszego. W drugim wypadku, oprócz zastosowania mapowania i podania strony, należało uzupełnić zapis o nazwę znajdującą się w źródle. Przy okazji zauważono, że brakuje odwołania do źródła KŚl III i SU I zawierających nazwę, jaką posłużono się w rekonstrukcji toponimu łacińskiego. W trzecim przykładzie, oprócz wspomnianych przekształceń, należało poprawić postać cytowanych nazw na zgodną z przekazem źródłowym. Czwarty przypadek jest ilustracją wariantu najkorzystniejszego z punktu widzenia korekty — po zmapowaniu należało jedynie uzupełnić zapis o brakującą stronę. W ostatnim z przedstawionych przypadków należało poprawić brzmienie nazwy oraz numer regestu. Tutaj uzupełniono jeszcze zapis historyczny o inny cytat podawanego dokumentu dyplomatycznego (SU II).
Ponieważ opisanego procesu korekty nie udało się w pełni zautomatyzować, podejmowane prace okazały się żmudne i czasochłonne. Aby nie wstrzymywać wydania słownika w wersji elektronicznej postanowiono dołączyć do niego wszystkie wpisy, nawet te, których jeszcze nie skorygowano. Ponieważ prace nad korektą są kontynuowane, wpisy te mogą ulec zmianie. Na przykład w chwili redagowania tych wyjaśnień w SENGŚ występuje ponad 800 referencji do Reg, które należy zmapować do CS.
Ze względu na pokrywanie się obszaru opracowywanego słownika z podobnymi rozwiązaniami dla ziem ościennych pojawiła się możliwość wykorzystania dodatkowego materiału referencyjnego. Postanowiono, by do opisów dołożyć referencje, w postaci hiperłączy, do materiałów źródłowych, które pierwotnie nie były rozważane przez autorów pierwotnej edycji. W kilku przypadkach pojawiają się więc odwołania do elektronicznej wersji Słownika historyczno-geograficznego ziem polskich w średniowieczu (http://www.slownik.ihpan.edu.pl/). Dla toponimów: Chełm Śląski, Gamrot, Imielin, Kopciowe, Kosztowy dodano odwołania do Słownika w obszarze Małopolski. Podobnie zidentyfikowano toponimy występujące w Historisches Ortsverzeichnis von Sachsen (https://hov.isgv.de/) — m.in. Białopole (Sommerau), Zgorzelec (Görlitz).
Część etymologiczna
W oryginalnym słowniku część etymologiczna pojawiała się na samym końcu danego hasła. W przypadku haseł zawierających kilka opisów toponimów wyjaśnienie pochodzenia nazwy dotyczyło zwykle ich wszystkich. Jednak w szczególnych przypadkach, gdy pochodzenie nazwy któregoś z toponimów wymagało dodatkowych wyjaśnień, w opisie etymologicznym stosowano przy tych wyjaśnieniach odwołania w postaci Ad 1, Ad 1-2 itp.
W trakcie cyfryzacji słownika przyjęto zasadę, że wspólna część opisu etymologicznego (dotycząca wszystkich toponimów wymienionych w opisie hasła) zostanie przypisana do toponimu abstrakcyjnego typu rozwinięcie (gdyż on reprezentuje główne słownikowe hasło), zaś części specyficzne, z adnotacjami, trafią do toponimów konkretnych. Pomysł ten zmaterializował się w postaci odpowiednio zaprojektowanego modelu danych oraz odpowiednio przygotowanego wsadu do bazy danych.
W efekcie użytkownicy korzystający z elektronicznej wersji słownika mogą zauważyć w opisach etymologicznych różnych toponimów konkretnych te same fragmenty. Dzieje się tak, gdy toponimy te stanowiły elementy tego samego hasła w oryginalnym słowniku. Elementy opisu etymologicznego przynależne toponimom abstrakcyjnym typu rozwinięcie i toponimom konkretnym można edytować osobno za pośrednictwem systemu edycji słownika (do którego dostęp mają tylko osoby uprawnione).
4. ZASIĘG OPRACOWANIA
Zasięg terytorialny opracowania wynika z przyjętych w wydaniu papierowych ram, w granicach historycznych Śląska ustalonych przez Władysława Semkowicza i Stanisława Arnolda oraz faktycznie używanych w poszczególnych tomach z przykładowym poszerzeniem o obszary łużyckie czy też czeskie (Kotlina Kłodzka) znajdujące się obecnie w granicach Polski. Na rysunku poniżej przedstawiono mapę oddającą zasięg przestrzenny opracowania zdefiniowany w pierwszym tomie.
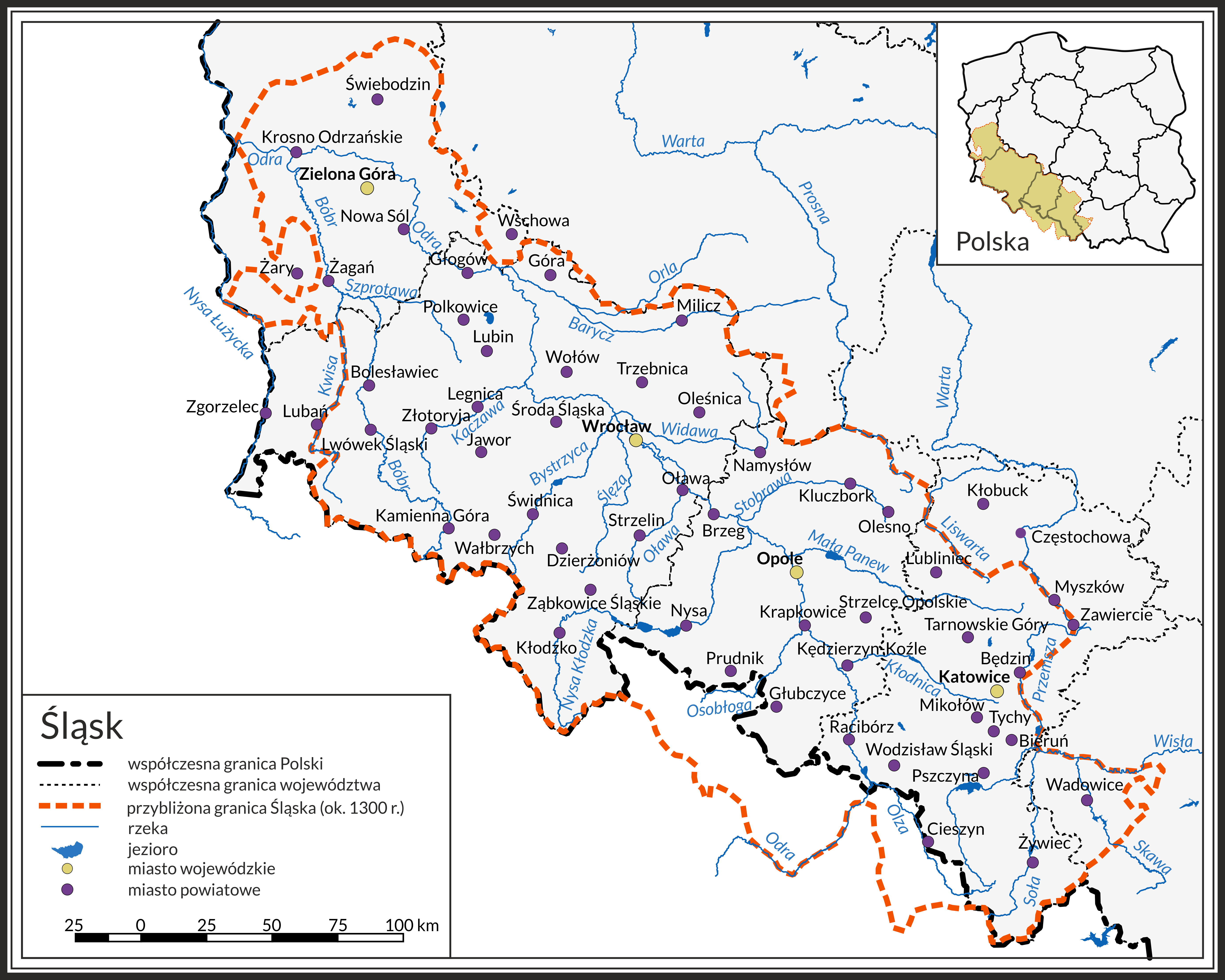
Mapa ta ma charakter poglądowy. Zaznaczonych granic zasięgu opracowania nie należy brać za ścisłe. Zamierzenia co do zakresu badań przeprowadzonych przez autorów słownika zmieniały się bowiem w czasie, co więcej, podczas cyfryzacji opracowano nowe obszary. Uściślono np. zasięg opracowania w obszarze części dawnych powiatów namysłowskiego i sycowskiego przekazanego Polsce w 1920 r. na mocy traktatu wersalskiego. Podczas cyfryzacji słownika udało się zidentyfikować tylko kilkanaście miejscowości z tego obszaru, a mianowicie: Buczek Mały, Buczek Wielki, Dobrzec, Frużów (jako Fruszów), Kałkowskie, Kotowskie, Krupa, Krzyżowniki, Niwki Książęce, Stary Folwark, Starza. Tak uzyskane wyniki zamieszczono w osiemnastym tomie, mając nadzieję na dalszą kontynuację badań.
Ze względu na podkreślany historyczny charakter słownika w nowej edycji przywrócono założenie z tomu pierwszego co do odwoływania się do historycznych terytoriów Śląska, początkowo w obszarze czeskim. Uzupełniono do tej pory nazewnictwo dotyczące większych miejscowości z czeskiego Śląska, miast powyżej 5 tyś mieszkańców: Havířov, Opava, Frýdek-Místek, Karviná, Třinec, Hlučín, Jeseník, Odry, Vítkov, Hradec nad Moravicí czy też Jablunkov.
Na dzień redakcji tego opisu do rozpracowania pozostają Świebodzin wraz z najbliższym otoczeniem wchodzącym jako enklawa pośród historycznych ziem brandenburskich jako obszar związany historycznie ze Śląskiem oraz enklawy księstwa Żagańskiego. Następnie należy rozważyć ujęcie obszarów łużyckich włączonych do pruskiej prowincji śląskiej w latach 1815 i 1825 oraz tzw. Nowy Śląsk (niem. Neuschlesien) istniejący w latach 1795–1807. Odnośnie okresu średniowiecza i wczesnej nowożytności uwzględnić można tereny księstw oświęcimskiego i zatorskiego — wcielonych w 1564 roku do Królestwa Polskiego, jako powiat śląski.
Ze względu na ogrom zagadnienia postanowiono nie włączać w ramy opracowania całości nieśląskich terenów obecnego województwo śląskiego.